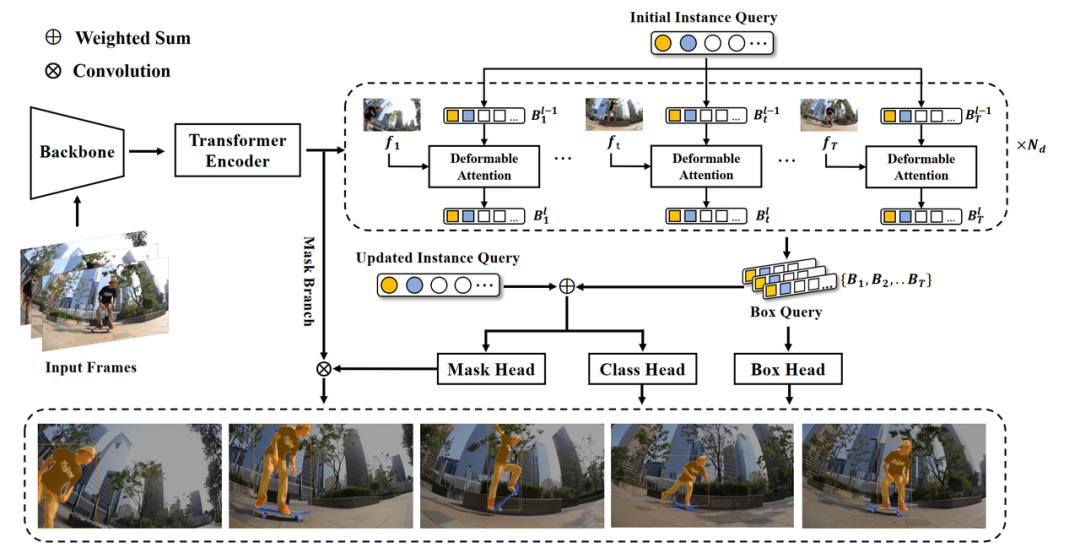
SeqFormer 是一个鲁棒、精准、简洁的离线视频实例分割模型,能够自然地解决物体在视频中的跟踪问题而不需要额外的跟踪分支和后处理操作。与现有的算法不同,SeqFormer 提出了一个 Query 分离的机制,将 Instance Query 分离成 Box Query,在每一帧分别去提取该物体对应位置的信息,然后进行聚合以在 video-level 更有效地表示每个 instance。
SeqFormer is a robust, accurate, neat offline model and instance tracking is achieved naturally without tracking branches or post-processing. SeqFormer locates an instance in each frame and aggregates temporal information to learn a powerful representation of a video-level instance, which is used to predict the mask sequences on each frame dynamically.
论文链接:https://arxiv.org/abs/2112.08275
代码:https://github.com/wjf5203/VNext


